CPP 변수와 데이터 타입
디스어셈블리로 내부 들여다보기
디버그 → 창 → 디스어셈블리로 C++ 코드가 어떤 어셈블리로 변환되는지 확인 가능.
int a = 10;
int b = 20;
int c = a + b;
이 3줄이 어셈블리에서는 10줄 이상이 된다. C++ 한 줄 ≠ CPU 명령어 한 줄
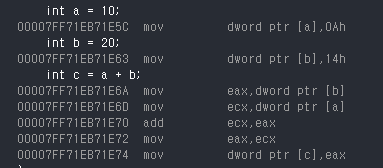
어셈블리 한 줄은 CPU 인스트럭션 한 줄이므로, 성능 최적화나 로우레벨 디버깅할 때 어셈블리어 지식이 필요하다.
주석
// 한 줄 주석
/*
여러 줄 주석
이것도 가능
*/
// Ctrl + K, C : 선택 영역 주석 처리
// Ctrl + K, U : 주석 해제
주석은 커밋만큼 엄격하진 않지만 팀단위의 프로젝트 시 컨벤션이 있는 경우도 있으니 아무렇게나 휘갈기는건 지양하도록 한다.
변수 선언과 초기화
int hp; // 선언만 (쓰레기값)
int hp = 100; // 선언 + 초기화
int hp{100}; // 유니폼 초기화 (C++11 이후)
지역변수를 선언하면서 초기화를 하지 않는 경우 메모리에 남아있던 예측 불가능한 데이터가 출력되면서 버그를 유발하기 매우 쉽다.
메모리 영역:
- 초기값이 있는 변수: .data 영역
- 초기값이 없거나 0인 전역/정적 변수: .bss 영역
변수 = 데이터를 담는 메모리 공간에 붙인 이름.
정수 타입
| 타입 | 크기 | 범위 (signed) | 범위 (unsigned) |
|---|---|---|---|
char |
1바이트 | -128 ~ 127 | 0 ~ 255 |
short |
2바이트 | -32,768 ~ 32,767 | 0 ~ 65,535 |
int |
4바이트 | -21억 ~ 21억 | 0 ~ 42억 |
long long |
8바이트 | -9백경 ~ 9백경 | 0 ~ 18백경 |
Visual Studio 확장:
__int64=long long(8바이트)- 표준 C++에서는
long long사용 권장
기본은 signed. int = signed int
char a; // signed (-128 ~ 127)
unsigned char ua; // unsigned (0 ~ 255)
어떤 타입을 쓸까?
특정하기 어려울땐 int 쓰면 됨. 하지만 메모리 최적화가 필요한 경우:
- 콘솔/모바일: 메모리 부족하니까 1바이트라도 아껴야 함
- 온라인 게임: 유저 10,000명 × 4바이트 낭비 = 40KB 추가 메모리
unsigned vs signed
unsigned를 써야 하는 경우:
- 배열 인덱스, 루프 카운터
- 음수가 절대 불가능한 데이터 (레벨, 점수 등)
signed를 쓰는 이유:
- 음수로 인해 버그가 생기면 바로 크래시가 날테니 빨리 찾는게 낫다
- unsigned/signed 를 통한 내부 변환중 버그 발생 가능성
정답은 없다. 팀 컨벤션 따르면 됨.
오버플로우/언더플로우
short b = 32767;
b = b + 1;
cout << b; // -32768 (오버플로우)
unsigned short ub = 0;
ub = ub - 1;
cout << ub; // 65535 (언더플로우)
왜 이런 일이 생기나?
- 정수는 고정 크기 메모리에 저장됨
- 범위를 벗어나면 순환됨 (시계처럼)
해결책:
- 계산 전에 범위 체크
- 더 큰 타입 사용
- 안전한 정수 라이브러리 사용
실제 사용 팁
성능 최적화: 함수 호출 비용
문제상황
vector<int> vec(1000000); // 100만개 원소
// 나쁜 예
for (int i = 0; i < vec.size(); ++i) {
// vec.size()가 100만번 호출됨
}왜 문제인가?
vec.size()는 함수 호출- 함수 호출 = 스택 프레임 생성 + 점프 + 반환
- 100만번 반복 시 불필요한 오버헤드
컴파일러 최적화의 한계
최신 컴파일러는 똑똑하다. 하지만 vector.size()는 순수함수가 아닐 수도 있다고 가정한다.
- 벡터가 다른 스레드에서 수정될 수 있음
- 따라서 매번 실제 크기를 확인해야 함
메모리 패킹: CPU 접근 방식
CPU는 4바이트 단위로 읽는다
메모리 주소: 0x00 0x01 0x02 0x03 0x04 0x05 0x06 0x07
Bad 구조체: [a___][bbbb][bbbb][c___]
↑패딩 ↑int ↑패딩왜 패딩이 생기나?
- CPU가 4바이트 경계에서 데이터를 읽는게 효율적
int b를 주소 0x01에서 시작하면 두 번의 메모리 읽기가 필요
실제 메모리 레이아웃
struct Bad {
char a; // 주소 0x00 (1바이트)
// 패딩 3바이트 (0x01, 0x02, 0x03)
int b; // 주소 0x04 (4바이트)
char c; // 주소 0x08 (1바이트)
// 패딩 3바이트 (구조체 크기를 4의 배수로)
}; // 총 12바이트
struct Good {
int b; // 주소 0x00 (4바이트)
char a; // 주소 0x04 (1바이트)
char c; // 주소 0x05 (1바이트)
// 패딩 2바이트
}; // 총 8바이트게임에서의 실제 영향
캐릭터 데이터 1만개:
struct Character {
char level; // 1바이트
int health; // 4바이트
char team; // 1바이트
};
// Bad 배치: 12바이트 × 10,000 = 120KB
// Good 배치: 8바이트 × 10,000 = 80KB
// 차이: 40KB 메모리 절약캐시 성능: 메모리가 작을수록 CPU 캐시에 더 많이 들어감 → 더 빠른 접근
확인 방법
#include <iostream>
using namespace std;
struct Bad {
char a;
int b;
char c;
};
int main() {
cout << sizeof(Bad) << endl; // 12 출력
return 0;
}결론: 큰 타입부터 작은 타입 순으로 배치하면 메모리 절약된다.